
近期,人工智能国际顶级会议2024 International Joint Conference on Artificial Intelligence(IJCAI 2024)在韩国济州岛顺利举行。
在IJCAI 2024上,昆仑万维2050研究院安波教授受邀进行了主旨为《From Algorithmic and RL-based to LLM-powered Agents》的Keynote演讲。安波教授同时是南洋理工大学校长讲席教授、人工智能研究院联席院长、人工智能系主任。

安波教授在IJCAI 2024上进行主旨演讲
作为人工智能领域的国际顶级会议,IJCAI 2024吸引了来自全球近三千名研究人员、工程师、行业领袖等的参与,是目前该会历史上规模最大的一届,会议主旨涵盖了人工智能与相关领域的众多研究方向。作为近年来的热点话题之一,大模型相关的研究也是IJCAI 2024最热、最活跃的领域之一。Agents作为当前大模型落地的未来趋势,被认为是解决各种复杂现实问题,迈向通用人工智能(AGI)的潜在路线之一。
围绕Agents这一主旨,安波教授回顾了其近二十年来在这一方向上不断深耕所取得的一些进展,总结了从中获得的经验教训,并展望了这一主旨未来的潜在发展方向。

安波教授在IJCAI 2024上进行主旨演讲
安波教授的分享包括三个部分:从早期基于算法的Agents,到近年来基于强化学习的Agents,再到最新的由大语言模型驱动的AI Agents。它们分别从问题的复杂性、算法的有效性、Agents的泛化性等角度逐层递进。
首先,早期基于算法的Agents的研究利用各种各样的优化技术(Optimization Techniques)来解决小规模问题。其中,研究的问题主要集中在安全博弈(Security Games)和追逃博弈(Pursuit-Evasion Games),取得了一系列的研究成果,特别是在安全博弈领域,其研发的算法被部署到现实世界的应用场景中,取得了显著的安全防御效果。

安波教授团队在Security Games领域的研究概览
然而,基于算法的Agents存在一定的局限性,如难以扩展到大规模的问题。相较之下,基于强化学习(Reinforcement Learning,RL)的Agents在解决长远规划(Long-term Planning)及大规模问题上具有显著优势。在这一方向上,安波教授分享了自2017年以来取得的研究进展,包括研发了一系列基于(深度)强化学习的算法,用于解决大规模追逃博弈问题;为工业界各种应用场景开发和部署了一系列强化学习算法,包括欺诈检测、推荐系统、量化交易(Quantitative Trading)等。
尽管基于RL的Agents已经在某些领域取得了一定的成功,其仍然面临着许多挑战,包括样本效率低(Sample-inefficient)、只适用于特定任务(Task-specific)、难以解决具有长程规划(Long-term Planning)和稀疏奖励(Sparse Reward)的任务等。
相比之下,由大语言模型(Large Language Models,LLMs)驱动的Agents(LLM-powered Agents)有其独特的优势,如丰富的、关于现实世界的先验知识(Word Knowledge)等。基于此,从去年(2023)开始,安波教授团队联合昆仑天工智能团队(Skywork AI),在LLM-powered Agents这一领域进行布局,在大模型的基础研究和应用上,均取得了不同程度的进展。
安波教授团队联合天工智能团队提出的TWOSOME框架,其利用强化学习(RL)来使LLMs与环境对齐,使得LLMs能够准确高效地与环境进行动态交互。用一句最简单的话来总结TWOSOME框架的基本思想,那就是“只有先合法,动作才会合理”。
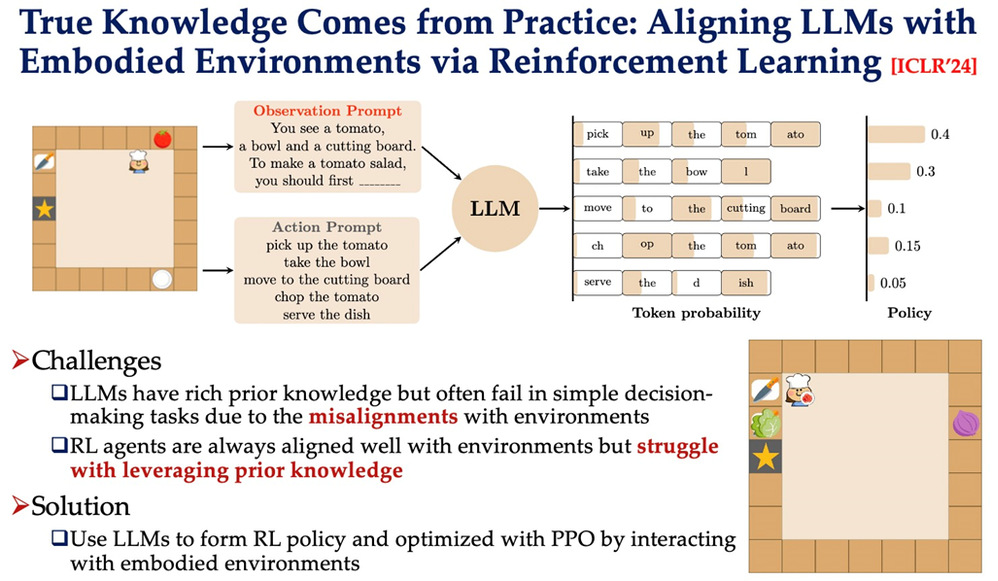
安波教授团队联合天工智能团队提出的TWOSOME框架
另一项备受瞩目的关于LLMs的基础研究《Q*: Improving Multi-step Reasoning for LLMs with Deliberative Planning》。这项工作对当前LLM的多步推理所面临的挑战进行了深入分析,提出将搜索算法(Search)如A* search,整合到LLM的推理过程中,极大地提升当前LLM多步推理的性能。

安波教授在IJCAI 2024主旨演讲中讲解Q*
在大模型的应用上,安波教授团队研发了一系列LLM-powered Agents,包括用于计算机控制(Computer Control)的Synapse、AgentStudio和Cradle,用于金融科技(FinTech)的FinAgent等。Cradle作为一个通用的AI Agent,无需依赖训练便能像人一样通过控制键盘和鼠标,实现任意开闭源软件的交互。Cradle不仅能够玩各种各样高难度的游戏如《荒野大镖客2》、《星露谷物语》、《城市天际线》、《当铺人生2》等,还能完成各种日常上网操作如浏览网页、发推特、下载paper、在美图秀秀里进行修图、在剪映里剪辑视频等。这些能力,体现了Cradle作为一个全能AI Agent的潜力。

安波教授在IJCAI 2024主旨演讲中讲解Cradle
此外,安波教授对LLM-powered Agents的未来研究方向进行了展望,包括:如何将LLM-powered Agents用于其他自然科学领域(Science),如药物和材料发现等;在未来的电子和物理世界中如何利用LLM-powered Agents高效地控制所有的设备;如何规范LLM-powered Agents的研究,确保其安全性和可控性,不会对人类社会造成损害;研发决策基座模型(Decision Foundation Models)等。
在演讲的最后,安波教授指出,基于算法的Agents、基于RL的Agents,和LLM-powered Agents这三种范式各有千秋,不存在某一种范式可以一劳永逸地解决现实世界中的所有问题。在未来的研究中,研究人员应该结合这三种范式,取长补短,研发能够自我提升的通才LLM-powered Agents(Generalist LLM-powered Agents),迈向通用人工智能的终极目标。

安波教授在IJCAI 2024主旨演讲中对Autonomous Agents进行的总结